FAQ 챗봇을 직접 구현하기 위해서는 input되는 사용자의 대화 문장의 의도가 무엇인지, 대화 내에 핵심 개체명이 있는지, 그리고 답변을 적절하게 생성하는것이 중요합니다. 그 중에서 대화의 의도가 무엇인지 파악하는것은 대화를 진행시키는데 있어서 핵심적인 기능인데, 양방향 LSTM 모델로 colab 실행환경에서 예측해보겠습니다.
1. 필요한 라이브러리 불러오기
colab에서는 tensorflow를 최신 버전으로 지원해서 별도로 설치하지 않고 import 하여 사용할수 있는데, keras도 tensorflow 1,2에서부터 통합되어 tensorflow.keras 형태로 불러와서 사용할수 있습니다. 한가지 여담인데 colab에서 tensorflow가 자동 업데이트 되어서 원래는 잘 작동되었는데 갑자기 오류가 나는 경우가 있습니다.... 만약 이와 같은 오류상황을 접하게 된다면 최신 tensorflow 버전에서 사용하는 라이브러리의 이름이 변경되었거나, 함수의 매개변수가 변경되었다던지 내용이 조금 변경된 경우일수 있습니다. 따라서 최신 버전 내용을 확인해보면서 코드를 수정한다면 오류해결에 도움이 될 수 있습니다.
"tf.__version__ " 코드로 현재 colab의 tensorflow 버전을 확인할수 있습니다. 저번에 확인했을때는 2.6.0이었는데 최신 버전으로 또 변경되었네요..! 저는 사실 이럴때마다 새로운 오류가 나타나지 않길 바랍니다..
2. 학습 데이터셋 불러오기
우선 맥도날드에서 작동하는 FAQ 챗봇으로 구현할것인데, 그렇다면 맥도날드 매장에서 고객이 어떤 질문을 할까요?
상품 정보를 묻거나, 주문을 하거나, 결제요청 등 다양하겠죠.. FAQ 챗봇인 만큼 대화 상황을 특정화 시켜 카테고리화 하여야 하는데, 다음과 같이 22가지 대화 상황으로 나누었습니다.

학습데이터셋의 경우 AI hub에서 제공하는 공공 데이터에서 이렇게 22가지로 정한 대화 상황에 맞는 데이터를 모아서 수작업으로 분류를 진행합니다. 데이터셋의 형식는 대화문장과 이에 맞는 의도를 짝지어 작성합니다. 대화의도 '3 주문확인'의 경우는 특정 상품을 말하며 주문하는 상황으로, 아래와 같이 작성합니다. 이와 같이 0~22의 각 상황과 맞는 문장을 분류하여 csv 파일을 제작합니다.

이제 제작한 csv 파일을 colab에서 불러올 차례인데, 그전에 우선 labels로 의도 종류를 선언해줍니다. 양방향 lstm으로 문장을 예측할때 정확도가 50%미만일 경우는 미매칭으로 정의하기 위하여 '미매칭'의도를 추가해줍니다.

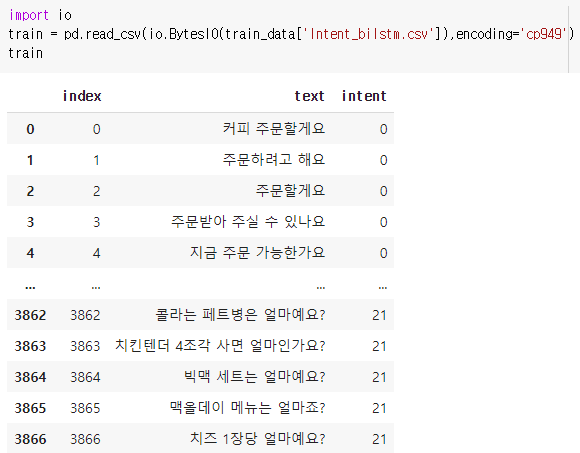
이제 구글 드라이브에 저장한 Intent_bilstm.csv 학습데이터셋을 불러와서 내용을 확인해보겠습니다.

구글 드라이브에서 파일 가져와 내용을 train으로 저장합니다. 문장의 경우 text 열에, 의도는 intent 열에 데이터가 있습니다. 총 3867개의 데이터를 구축하였습니다.
3. 데이터 정제
이제 text 데이터들을 lstm 모델에 학습시킬수 있도록 One-Hot-Encoding으로 변환하고자 합니다. One-Hot-Encoding은 단어 집합의 크기를 벡터의 차원으로 표현하고, 표현하고 싶은 단어의 인덱스에 1, 다른 단어의 인덱스의 위치에는 0을 부여하는 방식입니다. 두가지 과정을 통하여 One-Hot-Encoding을 진행합니다.
3-1. Vectorization
텍스트 데이터를 벡터화시킵니다. 여기서 각 단어에 고유한 인덱스를 부여합니다.(정수 인코딩)

모든 텍스트 데이터를 X_train,Y_train에 저장하고, keras에서 제공하는Tokenizer 유틸리티를 사용하여 각 단어에 시퀀스 번호를 부여합니다.

3-2. Embedding하기
이제 위에서 시퀀스 번호로 변환한 단어 목록들(정수 인코딩된 결과)을 One-Hot-Encoding으로 변환합니다.
keras의 to_categorical 유틸리티를 사용합니다.


train_y를 보면 의도 0 에는 [1,0,0,...0]으로, 의도 22에는 [0,0,0..,1]으로 One-Hot-Encoding 된것을 확인할수 있습니다.

4. Modeling 하기
이제 본격적으로 양방향 LSTM 모델을 만들어 학습데이터셋을 학습하겠습니다. keras에서 제공하는 Biredirectional 을 활용해 3개의 층으로 구성된 모델을 만듭니다. 층이 많아진다고 정확도 비율이 반드시 높아지진 않지만, 제가 시도해봤을때 3개일때 정확도가 가장 높아서 해당 갯수로 설정하였습니다. 학습데이터로 예측 의도는 0~22사이가 되므로 Dense는 22로 설정합니다. 여러개의 의도중에 하나로 예측하는것은 멀티클래스 분류와 같아서 손실 함수는 이에 적합한 categorical_crossentropy를 사용합니다.
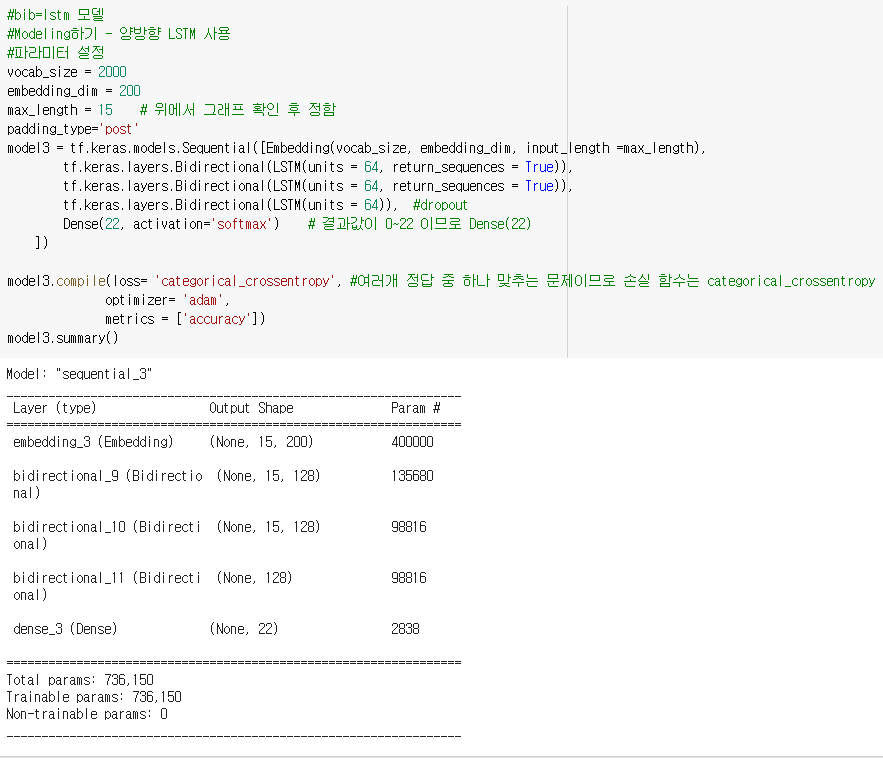
구축한 모델에 이제 학습 데이터를 학습시킵니다. 50 epochs의 결과 정확도가 0.9703 정도로 나타났네요!


5. 예측하기
거의 다 왔습니다! 이제 lstm_predict라는 함수를 만들어 text라는 input 문장이 들어오면 맨 처음에 의도 종류를 정의했던 labels에서 가장 확률이 높은 의도를 출력합니다. 아래 함수에서 pred[0]이 각 의도에 대한 확률분포의 행렬입니다. 여기서 가장 높은 값을 출력하게 됩니다.


그러면 이제 주문에서 결제까지 일반적으로 나타날수 있는 문장에 대해서 의도파악을 진행해보겠습니다!

꽤 높은 정확도로 의도가 적절하게 파악되었네요! 그런데 꼭 문장이 정확하게 의도 파악이 되지는 않습니다.

이렇게 학습데이터셋에 등장하지 않는 0~22 사이의 의도에 매칭되기 어려운 문장은 낮은 정확도로 엉뚱한 의도로 매칭이 됩니다. 처음에 언급했듯이 이렇게 정확도가 50%미만인 경우 미매칭으로 설정하고자 합니다!
위에서 정의했던 lstm_predict에서 약간의 코드를 수정하겠습니다.

달라진것은 pred 아래에 가장 높은 확률값인 pred[0][pred[0].argmax()]가 0.5 이상인지 아닌지 확인하는 코드가 추가된것입니다. 0.5 보다 크다면 원래 예측된 값을 확률과 함께 출력하고, 그렇지 않으면 '미매칭' 의도와 1에서 원래 예측된 확률을 뺀 값을 출력하도록 합니다.
결과를 볼까요...? '춥다'의 문장의 경우 미매칭으로 나타났습니다!

마치며
챗봇 구현에 있어서 대화의 의도를 파악하는 핵심적인 기능을 양방향 lstm 모델을 통해 꽤 높은 정확도(90% 이상인것이 많죠..)의 결과를 얻었습니다. 이 모델 한가지로도 어느정도 만족스러운 정확도의 챗봇 구현이 될테지만.. 혹시 좀 더 확실하게 더 높은 정확도를 얻는 방법이 없을까 하는 방법이 궁금하실수 있습니다. 어떤 방법이 있을까요..?
우선 공공 데이터를 제공하는 AI hub나 공공데이터포털 등의 사이트에서 학습 데이터셋을 좀 더 수집하는 방법입니다. 데이터 분류를 수작업으로 하는것이 조금 까다롭지만 하나의 방법입니다.
다른 방법으로는 여러가지의 예측 모델을 만들어서 앙상블 학습 을 하여 결과를 도출하는것입니다. 앙상블 학습 은 여러러 개의 분류기(Classifier)을 생성하고 그 예측을 결합함으로써 보다 더 정확한 최종 예측을 도출하는 기법입니다. 앙상블 기법에도 Voting, Bagging ,Boosting, Stacking 등이 있는데, 항상 앙상블 학습의 결과가 높은 정확도를 보장하지는 않으므로 여러 시도를 통해 어떤 기법을 사용할지를 선정해야 합니다.
마치는 글이 너무 길어지는데, 같은 학습데이터셋을 다른 알고리즘을 병렬 시행하는 방식의 Voting이 지금 이 FAQ 챗봇의 의도를 파악하는데 도움이 되겠네요. 이렇게 간략히 기법까지만 소개하고, 이만 양방향 lstm 모델을 통해 대화 의도 파악하는 글을 마치겠습니다.
'졸업 프로젝트' 카테고리의 다른 글
| 챗봇에서의 Mutinomial Naive bayes 알고리즘(다항 분포 나이브 베이즈), TF-IDF 적용 (0) | 2021.05.28 |
|---|---|
| colab에서 mecab 설치하기 (0) | 2021.05.28 |